The challenges of building LLM-powered clinical care navigation apps
And why the next model release won’t solve these problems
June 6, 2025
20 minute read
TL;DR: I spent 9 months building LLM-powered apps to help cancer patients navigate clinical care—chatbots with EHR integrations, appointment prep tools, and iOS apps (that Apple kept rejecting). I found real use cases and built working prototypes, but I discovered that LLMs aren’t ready for safe clinical use by patients. The core structural issues—context building, grounding, and usefulness—won’t be solved by the next model release. This is my personal experience; LLMs remain amazing for other use cases like prototyping the very applications illustrated in this post.
About 9 months ago, I set out to test a hypothesis:
Given that people already use general-purpose chatbots for health concerns, one could theoretically build a business around a specialized, LLM-powered app for clinical care navigation.
And presumably, this specialized approach could lead to higher quality, accuracy and usefulness compared to the off-the-shelf general solutions.
I chose an area that was very close to my heart: the problem of navigating the tough journey of cancer care.
This writeup captures—in perhaps an excessive amount of detail—my learnings from this nine month journey and the challenges I discovered.
The Use Cases
I spent a few months researching the most common user needs in this space to find a problem-solution fit. I talked to physicians, nurses, specialists, patient advocates, and of course, many patients.
My research led me to several key use cases that seemed feasible, desirable, and viable as product directions:
- Understanding one’s diagnosis and medical records
- Figuring out what questions to ask providers and preparing for visits
- Dealing with treatment side effects
- Researching alternative treatment paths
- Patient self-advocacy and empowering caregivers
- Capturing and debriefing interactions with providers
The Prototypes
One of the most fun parts of this journey has been the ability to go back to coding after years of “product managing.” The tools I used (mostly Cursor + Claude) kept getting better almost monthly. And I grew with them. I’ve developed a pretty sophisticated symbiosis with AI-coding toolkits that almost warrants its own article—though there’s already a lot being written about this, so I’m not sure I have unique insights to add. Being able to turn ideas into real working prototypes in a matter of hours/days was very transformative in my explorations.1
Here’s what we built:2
1. A Series of Mini Apps
- One that facilitated talking to a chatbot specially designed to pull data from authoritative sources (e.g. cancer.org) and annotating complex medical terms in its responses to meet the average user’s medical literacy level
- One that facilitated talking to a PDF export (thousands of pages) of a patient’s MyChart data while linking to the specific parts of the PDF file to validate citations in the model’s responses
- One that helped people get a “second opinion” on a question using Deep Research features from different platforms while passing their entire health records through a MyChart PDF export
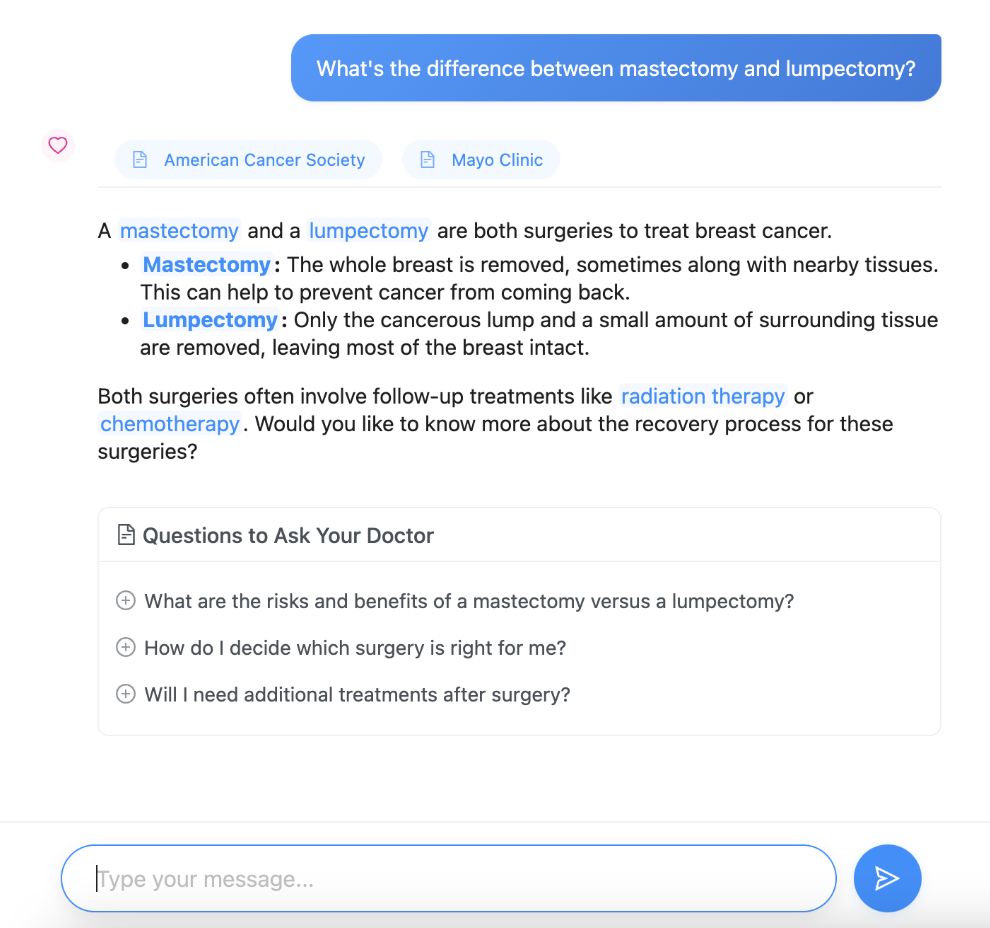
One of the mini apps (chatbot) that annotated medical terms and cited authoritative sources.
2. The first major Web App
After building the series of mini apps, I ended up building a full web app that allowed people to connect to their provider’s EHR instance through a FHIR interface so they could:
- Generate an overview of their care and summarize their health records with an LLM
- Generate insights about their journey that they could use as conversation starters with an LLM
- Ask questions about their history
- Create a list of notes and insights to discuss with their providers
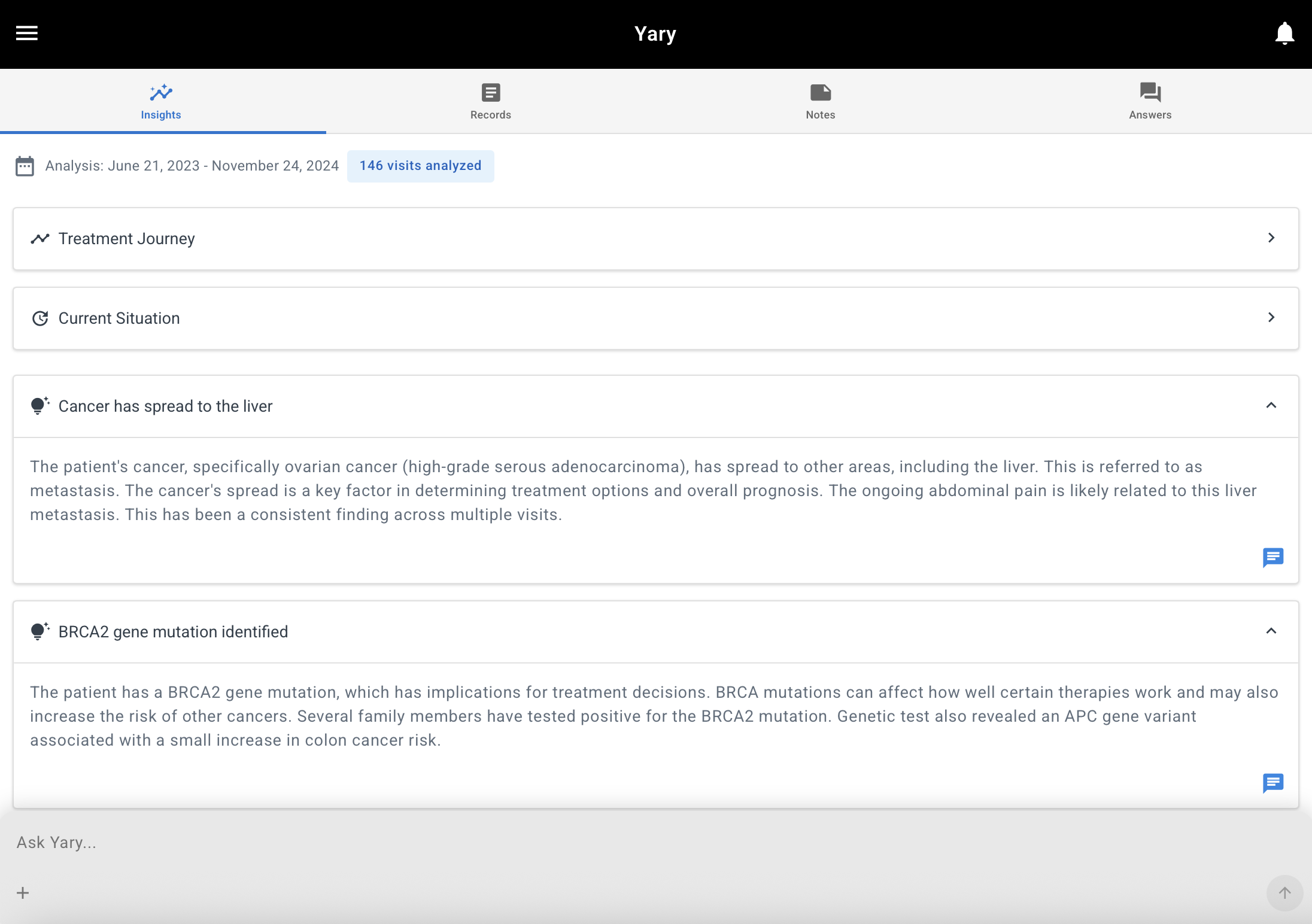
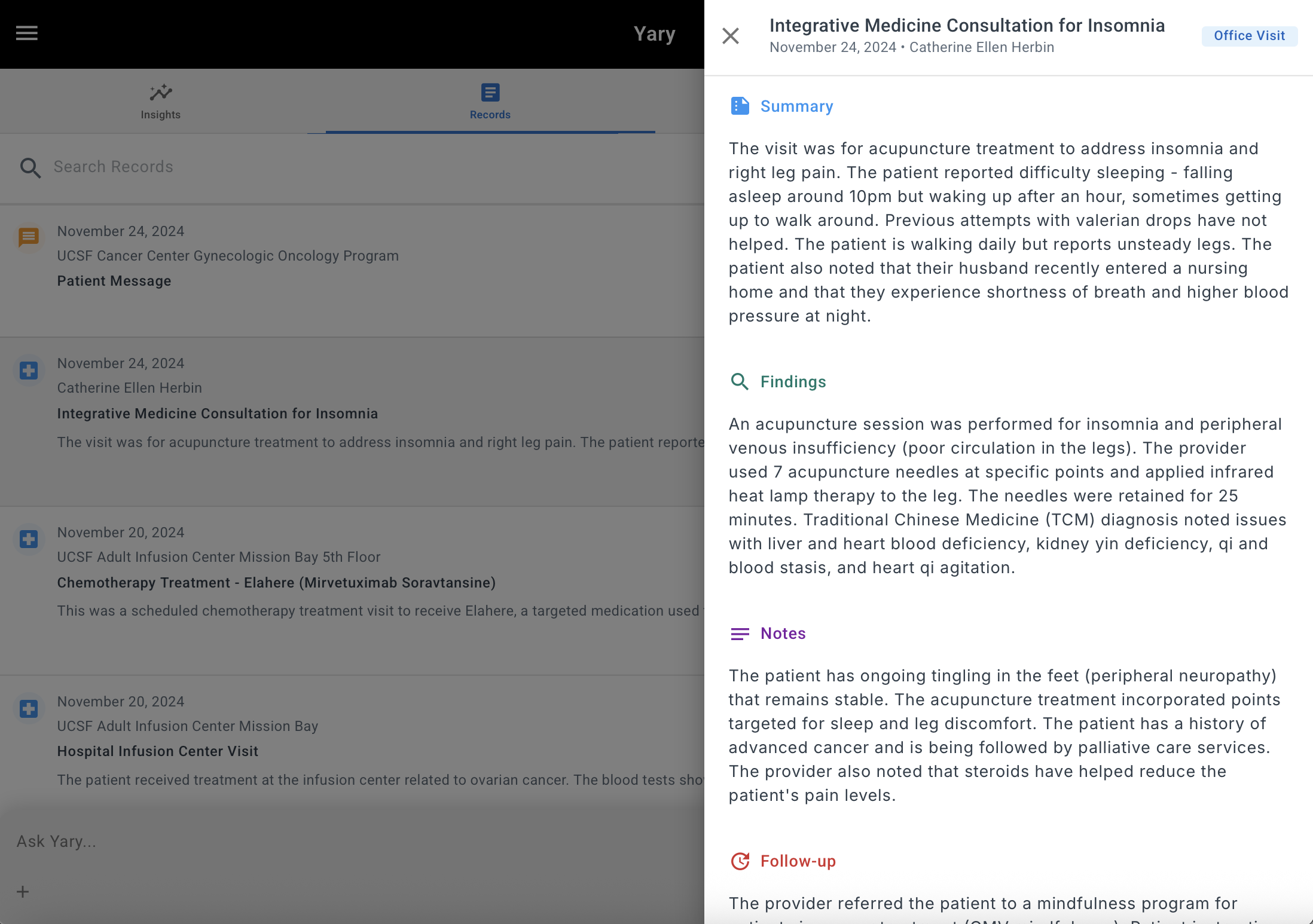
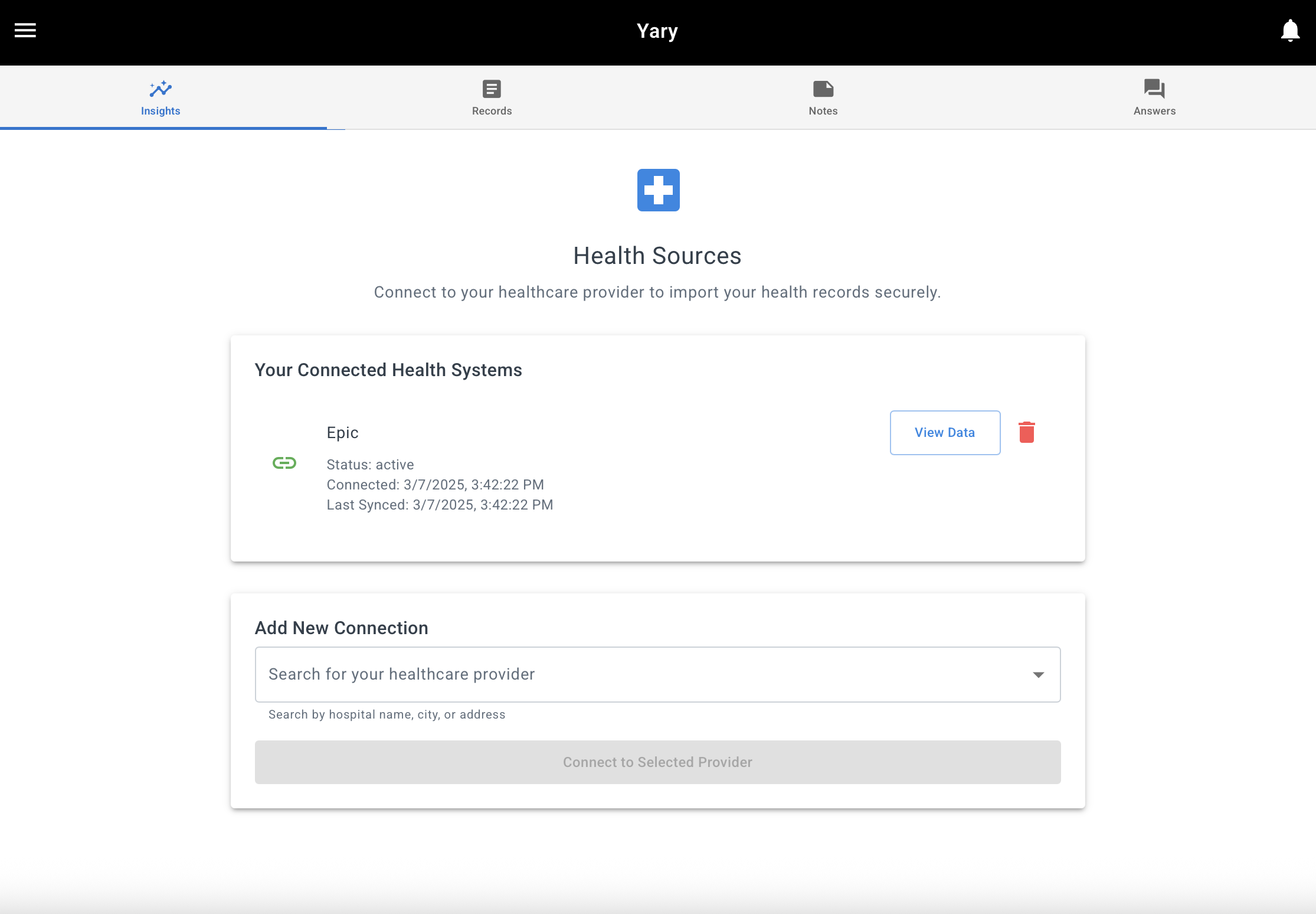
Screenshots from the first web app that allowed users to connect with their EHR system and chat with the results
3. An iPhone App (The Apple Saga)
One of the native iOS apps that I built to ground an LLM on the user's HealthKit medical records
Most of my time was spent building a native iOS app (in Swift) that did everything above but also let users connect the app to their medical records through Apple’s HealthKit. Why go the iOS route? I discovered that fetching user data through a third-party FHIR data acquisition service was prohibitively expensive. It also required users to trust not only us, but also our third-party service with their sensitive health information. Meanwhile, Apple had built a solution with the most reach in the US, Canada, and UK for fetching patient records—and it was FREE. So I figured it was worth building a snappy native iOS app on top of this functionality. I added features to record appointments, transcribe them, and discuss them with an LLM grounded in both the appointment and the user’s health history.
Apple never approved the app. I never got a straight answer as to why, but I suspect it was because they did not want to allow off-device processing of users’ health data, even with clear explanations and user consent.
I even built a much simpler version that did a single LLM call to generate the user’s health journey (demo). I labeled it with all sorts of disclaimers and drafted a very privacy-centered Privacy Policy. The policy indicated that data would only be processed on a HIPAA-compliant backend and never stored beyond processing time on Google’s Vertex AI, which we had a HIPAA BAA (Business Associate Agreement) with. My apps are still in review and have been rejected 10+ times. It’s starting to feel like Apple is simply stalling me. I still don’t know whether I can run a remote HIPAA-compliant LLM on HealthKit medical records data even without storing any patient data. Given what I will explain later in this article, while this issue was a catalyst, it was not the root cause of my decision to pause this direction.
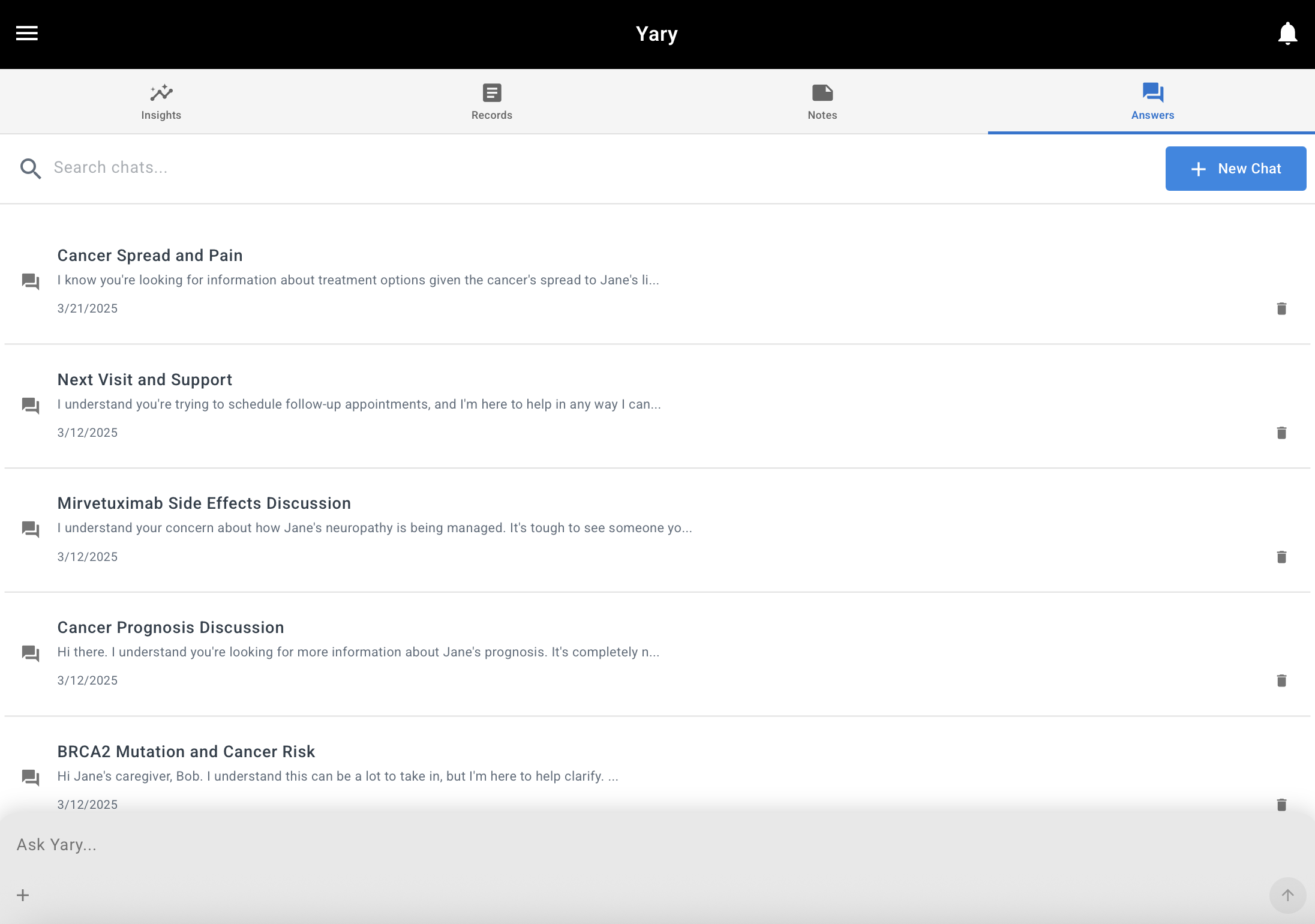
4. Another Web App
The final web app built as the final attempt to test the original hypothesis
In response to Apple’s App Store rejections, I recreated the iOS app as a web app. By this time, Claude 4 had come out and I knew what I wanted to make, so this iteration went by at least 5 times faster than the iOS app. I also added a way to detect health “memories” from chatbot conversations (using function calls) to reduce the barrier of asking users to trust us with all their medical records. I later added the ability to bring in MyChart data to this app too.
I thought about open-sourcing all these apps. But their reliance on ever-changing web services makes them quickly obsolete.
Reflecting on the Limitations
While any attempt to summarize the limitations of LLMs is doomed to become obsolete within weeks due to their seemingly exponential growth, I’d like to think that I gave this idea an honest try.
If I had to sum up my learnings in one sentence: LLMs aren’t safe for direct clinical use by patients—not yet.
While I had different product iterations ready for public testing, my conscience didn’t allow me to put them up for people to freely try. I would literally dream of someone using them, getting wrong results, and feeling responsible for the suffering they would experience. Maybe this mentality makes me unqualified for working in healthcare.
The Root Causes
As usual, there are a million reasons why a startup idea might fail. It’s expected for startups to pivot a few times until they find something that works. Much of it is timing, founder problems, and systemic external issues (like the mess that is the US Healthcare system). But I have enough data to say, with 90%+ confidence, that I cannot make this idea work within a reasonable timeframe. This would be true even if every other factor was held constant. Sure, it might work if LLMs became hallucination-free and perfectly steerable tomorrow. But knowing a bit about the technology behind them, I’m not sure this will happen anytime soon (though I’ve been working on and waiting for that day for two years and counting).
The way I break down the key failure reasons in my head:
- Impossible context building
- Impossible grounding
- Limited usefulness
The rest of this writeup explains these three core challenges.
1. Impossible Context Building
The promise that patients should own and have access to their personal records dates back many years. There are countless trials and startups trying to make this dream a reality. Some have failed. Some have been acquired by big-tech companies (e.g., Gliimpse and Ciitizen, both built by the same founder who is now creating Selfiie 🤨).
But what’s clear is that no single person I know has access to all their data. Yes, you can log into MyChart and get an intentionally convoluted dump of your records—a mix of PDFs, structured data, and clinical notes that would challenge even the most sophisticated parser. But that’s just one health system. What about the urgent care visit from five years ago? The specialist you saw in another state? The dental records that might be relevant to your cancer treatment?
The fragmentation is staggering. Each provider uses different systems, different formats, different standards. Even within the same hospital network, data might be siloed across departments. The promise of interoperability remains largely that—a promise. And without comprehensive context, any LLM system is working with a dangerously incomplete picture.3
2. Impossible Grounding
I tried almost every tool in the toolbox: RAG (Retrieval-Augmented Generation), Function Calls, MCPs (Model Context Protocols), passing everything to the models with large context windows. There’s always some part of the system that fails. And the errors aren’t recoverable or transparent, which makes them really hard to reliably avoid.
It’s not like traditional systems where you actually get an error. The model just makes a best “guess” and confidently gives an inaccurate response. Or it gives a response that exposes the prompt and inner workings of the system. I see this frequently with ANY system that has an open chatbot interface.
While this issue is forgivable in low-stakes use cases, when users ask a system for information that could lead to life-or-death outcomes, this behavior breaks their trust. Imagine talking to your nurse and at some point in a deep conversation, they just confidently stop making sense. Your relationship with that provider is over.
And yes, I know the theory that as long as your solution is better than the alternative human option, it’s alright. But in a clinical setting, that idea is dangerous. Yes, ChatGPT and Claude already operate on that premise. But at least they’re not marketing a health product. If they did, I bet they’d be in massive legal trouble. I, however, was setting out to make a health product and don’t have the legal team that big tech companies have.
3. Limited Usefulness
Even when everything worked in terms of context assembly and grounding, the likelihood of users actually knowing what to do with the model’s output was low.
Let’s take the case of hard decisions about surgery versus chemo for a cancer patient.
Assume the model knows everything about the patient’s medical history. It’s asked whether the patient should do chemo or surgery. First, this question is medical advice. So from a legal perspective, we should punt.
If we punt, the patient assumes the system is useless because they could just use ChatGPT or Claude and get an answer.
So we shouldn’t punt? The best we can do is what ChatGPT does: give a best-effort answer sandwiched in disclaimers. My argument is that for hard questions, any answer is tricky.
The trickiness arises from the fact that there is no easy right answer.
I got to this conclusion when researching my late aunt’s case. She was diagnosed with Stage 4 pancreatic cancer. Her family had to decide if she should get chemo or join an immunotherapy clinical trial. The answer to this question is so multifaceted. The LLM’s eagerness to please makes it very likely to start spewing information to the user, giving a gigantic list of options, and listing their pros and cons. Sure, that’s better than no information, but the truth is Stage 4 pancreatic cancer is barely survivable. My aunt passed away about a month after her diagnosis even though she was in her sixties.
In that situation, the patient and caregivers are looking for clarity and less information. Not more options and content to overwhelm them. The right “answer” for them was really to spend more quality time with each other rather than endure more pain and suffering through treatment.
This taught me that the most critical healthcare decisions aren’t just clinical—they’re deeply human, contextual, and often about quality of life rather than quantity. It’s impossible to give a good answer if you just focus on clinical aspects of someone’s life. There are moral, religious, and personal aspects that need to be considered. And this takes us back to the first problem: it’s impossible to meaningfully know that context at large scale.
The Business Model Reality Check
Aside from these structural challenges we still haven’t even considered answering the fundamental question: how might one make money from this idea?
The usual business models for direct-to-consumer health tech companies are:
- Selling the data
- Showing ads
- Charging for subscriptions
- Partnerships (i.e. B2B2C) with providers, payers or pharma
Options 1 and 2 are out of the question for me. Health data is different. It’s a part of you.
Option 3 is the most common path, but faces two major challenges: (a) patients notoriously have low willingness to pay for health tools, and (b) the product needs to be strictly better than alternatives. When we frequently punt on hard questions while ChatGPT and Claude do not, it’s tough to justify the subscription cost.
Option 4 is an area that I also explored, but frankly, due to the lack of feasibility and usefulness I described above, I didn’t see a major path for success there either.
So, Now What?
Are there other clinical health problems that LLMs could help with? Absolutely. Does the idea of building a patient-facing clinical cancer care navigation app make sense for an early-stage startup? Not yet. And my reasoning is based on the structural issues I’ve outlined which I don’t think will disappear with the next LLM model release.
A question that led me to clarity is: How would I now deal with a personal cancer case? How would I use technology for it?
My answer, after thinking about this use case for so long, is that I would actually just use off-the-shelf tools. I would upload all the important parts of my data (personalized context assembly) to a Claude Project and run Deep Research agents on my questions. I would record my appointments on my iPhone’s Voice Memos and upload them to that Claude project to reference them. I would also use Claude to think about the best questions to ask for my upcoming appointments.
Yes, it’s not HIPAA compliant, but so what? They say they’re not training on my data, and their claims on respecting data rights are as good as any other company. Their security measures are better than a small startup, even if the startup has gone through a HIPAA checklist and has the documentation for it. And if I’m too worried, I can only give them parts of my data that aren’t identifiable.
Is this something that only highly capable users can do? Yes. But my argument is that only those highly capable people can actually process these answers. Just because chainsaws might now cost zero doesn’t mean we should give one to everyone.
What’s Next?
- I wrote this long writeup for myself to make sense of my past 9 months. I would be delighted if it helps someone else or at least helps others start where I left off. There is a major problem-solution fit for using LLMs for navigating complex diseases. The big question for me wasn’t whether people should use them (assuming they know what they’re doing). The big question was whether someone should build a new company around this concept today.
- I want to teach the useful things I’ve learned to caregivers and patients. If they’re at the edge of knowing how to use these tools, I want to make them more productive. An educational module could achieve that with relatively low cost. I might also do some talks at cancer support groups.4
- I’ll probably try something else in the oncology space or explore the non-clinical aspects of care navigation (e.g. financial navigation). But I need to do more market research first.
Would I do everything the same if I could go back 9 months? Probably. How would I do it differently? I would be nicer to myself. I had picked a very complex problem. I should have had more grace for my struggles in navigating it.
I hope you found this writeup useful.
As a former PM, I think we can now replace much of our traditional PRDs with AI-coded prototypes paired with clear evaluation criteria and initial test sets. ↩︎
I would not have been able to do the work I mention in this article without the generous and heartfelt help from a group of incredible collaborators. While this list is incomplete, I would like to thank Daniel Matiaudes (my design partner), Joan Venticinque, Dr. Jeanne Shen, Dr. Matthew Lugren, Srecko Dimitrijevic, Jenny Rizk, Jake Knapp, Jeanette Mellinger, John Zeratsky, Eli Blee-Goldman, Dr. Howard Kleckner, Rob Tufel, Thushan Amarasiriwardena, Henry Schurkus, Anna Brezhneva, Naxin Wang, Cody Sam, and of course my wife Rana, who was my very patient sounding board over the last 9 months. I also want to cherish the memory of my beautiful and loving aunt who passed away while I was working on this idea. ↩︎
You might rightly counter that even doctors do not have the full context for a patient’s case. My argument is that doctors—due to their training, specialization and contextual understanding of the local systems they operate in—have a much better ability to figure out missing pieces of information. The first thing that a doctor usually does is ask for the full details of your relevant tests and symptoms. The first thing an LLM does is … well, it eagerly tries to shower you with tokens. ↩︎
If you’re interested in having me speak at your cancer support group or organization, feel free to reach out! Contact details are on my about page. ↩︎