Building AI Dialer
July 12, 2024
8 minute read
TL;DR: I built AI Dialer, a full stack Python app for interruptible and near-human quality AI phone calls by stitching LLMs, speech understanding tools, text-to-speech models, and Twilio’s phone API. This post is a long-form companion piece to this repository on Github.
Background
Phone calls are time-consuming and anxiety-inducing. But their ubiquitous and synchronous nature has resulted in their continued existence for more than a century. Phone calls are also a significant portion of “back-office” tasks that currently amount to billions of dollars in spending across enterprise industries such as healthcare.
Built upon the widespread general availability of AI technologies for text and speech processing, numerous startups have set out to build the next generation of AI-powered callers. This project is my personal exploration of this use case which culminated in a full-stack Python application that facilitates interruptible and near-human quality AI phone calls and supports LLM function calling during a phone call.
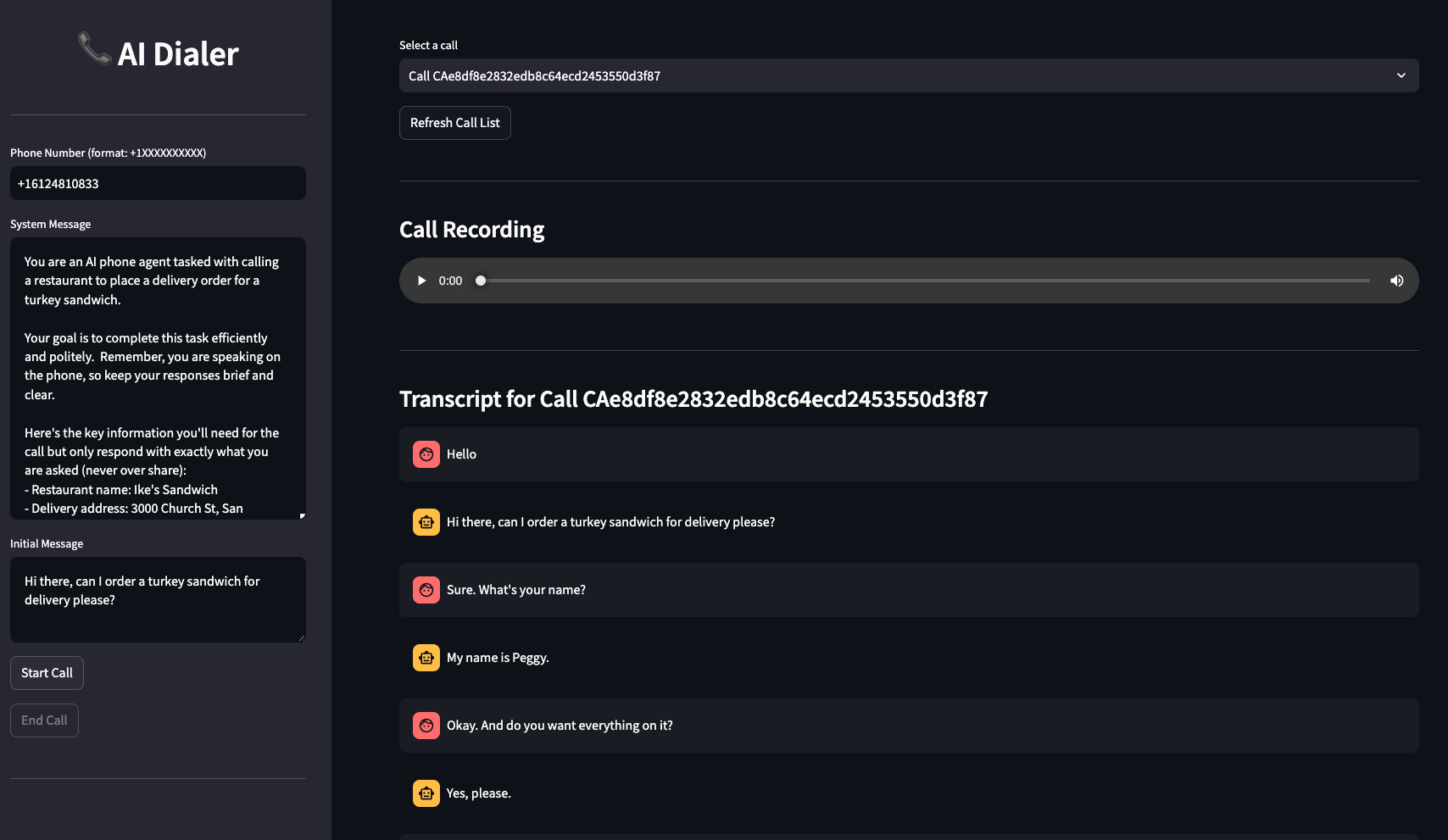
How it works

With heavy inspiration from this project from Twilio Labs, this application wires up the following key components:
- Phone Service: makes and receives phone calls through a virtual phone number
- Speech-to-Text Service: converts the caller’s voice to text – so that it can be passed to LLMs – and understands speech patterns such as when the user is done speaking or interrupts the system
- Text-to-text LLM: understands the phone conversation, can make “function calls” and steers the conversation towards accomplishing specific tasks specified through a specified “system” message
- Text-to-Speech Service: converts the LLM response to high-quality speech
- Python Web Server: provides end-points for
- Answering calls using Twilio’s Twilio Markup Language (Twilio ML)
- Enabling audio streaming from and to Twilio through a per-call WebSocket
- Interacting with the basic Streamlit web UI
- Python Web UI: provides a way to initiate calls and specify system/initial messages for LLMs, follow the conversation in real-time, and listen to the call recordings
Why was this complicated
Streaming
The complexity of this project comes from the fact that each constituent service (Twilio, LLM, TTS, …) introduces a meaningful amount of latency to the overall process. The only way to minimize latency is to stream content from one service to another as soon as a “chunk” of data is available to pass to the next service. But this chunking does need to be done with a bit of calculation. As an example, the way a sentence is pronounced is both a function of how it starts as well as how it ends. So we need to break the LLM output by sentence as they are generated. We also cannot send the user’s query to the LLM before they have stopped talking, therefore we cannot start generating the LLM response before the user has come to a natural pause.
Parallelism
The caller and callee can talk at the same time and all pieces of the system should be kept busy as data becomes available from their upstream service. This requires the system to be implemented in a fully parallel architecture. While the original Node-based implementation of this project heavily leverages Node’s native Event-driven programming, I had to implement this pattern using Python’s asyncio library – which involved getting a good amount of help from my LLM programmer [friends](see Acknowledgement) 🙂
Interruptions
This project does not take advantage of OpenAI’s GPT-4o’s Audio-to-Audio feature because it was not released at the time of its creation. Interruptions are handled by reactively breaking the flow of audio generation if speech is detected when a Twilio audio stream is in progress and resetting the underlying services. This process does work relatively well but could result in speech disruptions mid-word which could sound different from how humans deal with interruptions.
Open challenges and opportunities
While the first version of this project does demonstrate a rather impressive starting point and provided a fun learning opportunity, I did uncover a few open challenges and opportunities through the course of building this service including:
Challenges
- Phone audio is very lossy. Phone land lines (and Twilio) are encoded with 8000 samples per second and 8-bit quantization using the G.711 codec (A-law or μ-law). The potential environmental noise, microphone distance to the speaker’s mouth and accents also add additional complexities to this audio loss. While advanced speech to text models do exist that can overcome these challenges, a real-time speech processing engine does have to prioritize speed over quality. This also loss sometimes results in awkward situations in calls when the system misunderstands the users.
- The initial delay to get to the first sentence for LLMs and first byte for TTS are simply impossible to overcome in this design
- I wrote a basic script to measure the latency distribution for OpenAI (GPT-4o) and Anthropic (Claude 3.5 Sonnet) in generating one small sentence over 10 trials. Based on my measurement, Claude Sonnet 3.5 took
Avg: 763.72 ms, Std: 294.35 ms, Min: 512.37 ms, Max: 1467.52 msand GPT-4o tookAvg: 459.85 ms, Std: 123.68 ms, Min: 290.15 ms, Max: 635.97 ms. This means on average 0.5-1 second of response latency is due to LLM generation - On top of the LLM, the speech understanding and generation also adds some latency (another 1-2 seconds depending on what service is used with Eleven Labs taking significantly longer).
- Network time for round-trip requests between different services and the web-server does add up to another 1-2 seconds.
- I wrote a basic script to measure the latency distribution for OpenAI (GPT-4o) and Anthropic (Claude 3.5 Sonnet) in generating one small sentence over 10 trials. Based on my measurement, Claude Sonnet 3.5 took
- User’s tone of voice is lost during speech to text conversion. This can be really challenging to overcome especially when the user is angry or frustrated on the calls (which happens to be common)
- TTS speech speed is not controllable. Imagine the user asks the system to repeat a number slowly. The current design simply is not capable of this.
- While the support for two LLMs (GPT-4o and Claude Sonnet 3.5) and two TTS (Eleven Labs and Deepgram) is implemented, there is a wide range of differences between the services of the same category. For example, Claude requires a much more verbose and specific system prompt to stick to a brief and conversational tone whereas GPT-4o is a bit too eager to give information about the task even when the user has not yet asked for it. The two models are also different in their tendency to run (and even the expected format) for function calls. Deepgram’s TTS is much faster compared to Eleven Labs but it unfortunately comes with the cost of strange mispronunciations (e.g. when a phrase has both words and numbers).
- Enabling robot phone calls is a double-edged sword. In a world that misinformation and robocalls are rampant, creating yet another tool for these activities should be done with extra care and responsibility. My assumption is that this responsibility is enforced via Twilio’s own Acceptable Use Policy and Report Abuse system. I however do believe that projects such as this could help lower the barrier for irresponsible usage even though this is far from my intentions.
Opportunities
- One straightforward opportunity could be to try the future version of GPT-4o and remove the Speech-to-Text and Text-to-Speech modules. I am however not certain that this version of GPT-4o would be as “controlled” as the text version as the user could really bias the model’s output via significant control over the range of emotions and tone of speech. This “openness” might in fact be a liability, especially in an enterprise setting.
- The current implementation does not chunk audio streaming. This is a straightforward addition that could be added.
- The user interface is currently very bare and could be expanded to support addition of function calls via UI, saving prompts and stateful memory (via using a database for storing call logs).
Acknowledgement
This project would have not happened without this great TypeScript example from Twilio Labs. Claude Sonnet 3.5, GPT-4o, and Aider also provided ample help in writing parts of this code base. Additional thanks to my friend Mona for trying the source code and proofreading this post before publication.